


What is Data Manipulation?
Data manipulation is one of the techniques in the life cycle of data analysis. It refers to the process of organizing the data by adjusting certain rows or columns with which, it becomes easier to read and understand. We have a separate programming language called Data Manipulation Language (SQL) to proceed with all kinds of adjustments (inserting, deleting, modifying, etc).
Credits of Cover Image - Photo by Tower Electric Bikes on Unsplash
Note - This article mainly focuses on certain methods like apply() and map() - helpful to manipulate the data. These methods are pandas methods.
General Purpose
The ultimate goal of any program written in any language is to complete the task as fast as possible by consuming less memory and time. Using these built-in methods can be beneficial as they are optimized keeping all the constraints. The same implementation can be achieved by writing our own custom function, but this cannot be as efficient as using the built-in method, and moreover, this can sometimes turn out to be very tedious.
apply()→ this method is used to manipulate the entire data frame or one single column (series) when passed a function.map()→ this method is used to manipulate only one single column (series) at a time when passed a function.
Problem Statement - 1
Given a numerical data frame, compute the square of each number from each column and obtained a new data frame. Further explanation can be seen in the below figure.
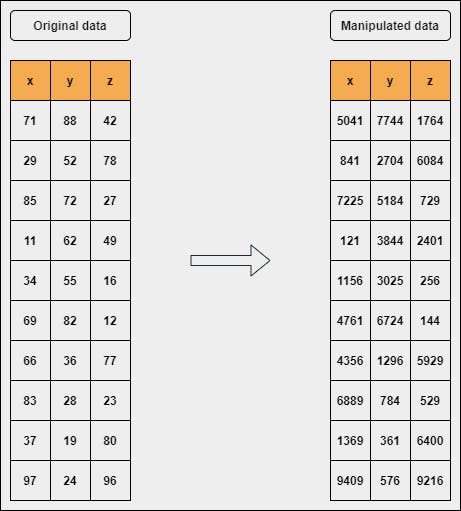
The data which is on the left side is the original data and the right side is the manipulated data which is basically the square of the number.
Custom Function
The custom function (user-defined function) that we can think of solving this problem can be like -
def sqaure_data(dframe):
cframe = pd.DataFrame()
for col in dframe:
square_col = []
for each_val in dframe[col]:
square_col.append(each_val ** 2)
cframe[col] = square_col
return cframe
The function is using two for loops which can make the program execute slowly when data is very large. This is definitely not the right thing to practice in original data analysis tasks.
apply() Method
Let's say, the original data (on the left) is stored in a variable called df. By using apply(), this task can be computed easily with just one line.
adf = df.apply(lambda x: x**2)
That's it! The above returns the manipulated data - stored in the variable adf. The only caveat in using this method is that it is important to make sure the data contains no NaN values and all the values are numeric in nature (in the sense, there should not be any text data).
map() Method
As the method apply() is used, map() can also be used but map() only manipulates a single column at a time. It cannot be used to manipulate the entire data at once.
mdf = pd.DataFrame()
for col in df:
mdf[col] = df[col].map(lambda x: x**2)
for loop is simply used once just to iterate through columns but not each value in a column. This is far better than the first method but not as better as the apply() method.
apply() can perform the same task that map() can. There are advantages and disadvantages of both methods. Quick data processing is a must before using these methods in practice.
Problem Statement - 2
Given a numerical data frame, replace the values that are less than 25 with 1000. Further explanation can be seen in the below figure.
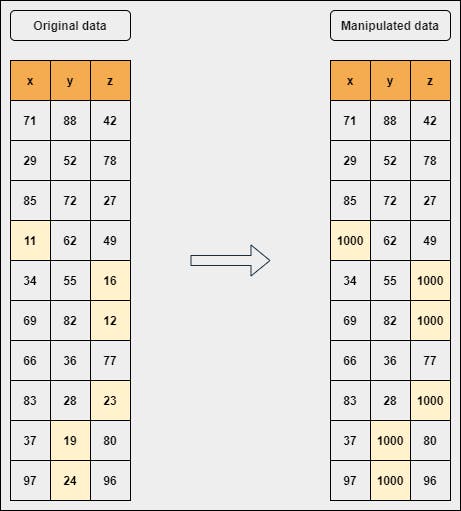
The data which is on the left side is the original data and the right side is the manipulated data which is basically the replacement of those numbers with 1000 that are less than 25.
Custom Function
The custom function (user-defined function) that we can think of solving this problem can be like -
def replacer(dframe, cval=25, with_=1000):
rframe = pd.DataFrame()
for col in dframe:
rvals = []
for each_val in dframe[col]:
r = with_ if each_val < cval else each_val
rvals.append(r)
rframe[col] = rvals
return rframe
As usual, this uses 2 loops that can be hectic if the data is very large.
apply() & map() Method
This case cannot be handled by one line of code, instead, a loop is used that goes through each column.
rdf = pd.DataFrame()
for col in df:
rdf[col] = df[col].apply(lambda x: x if x > 25 else 1000)
or
rdf = pd.DataFrame()
for col in df:
rdf[col] = df[col].map(lambda x: x if x > 25 else 1000)
Here, apply() is similar to map(), apply() is not utilized as robustly as it had been utilized in problem statement 1. It is because an extra conditional statement is introduced and thus, cannot be achieved in one line of code.
To compute this in one line of code, the method applymap() can be used. It is the combination of both apply() and map().
applymap() Method
rdf = df.applymap(lambda x: x if x > 25 else 1000)
That's it! The above returns the manipulated data - stored in the variable rdf. The only caveat in using this method is that it is important to make sure the data contains no NaN values and all the values are numeric in nature (in the sense, there should not be any text data).
Conclusion
The article encompasses the core details on how to manipulate the data effectively by certain methods.
Methods included here are
apply(),map(),applymap()which arepandasdata manipulation methods.The use case of each method is explained clearly with problem statements.
Buy Me Coffee
If you have liked my article you can buy some coffee and support me here. That would motivate me to write and learn more about what I know.
Well, that's all for now. This article is included in the series Exploratory Data Analysis, where I share tips and tutorials helpful to get started. We will learn step-by-step how to explore and analyze the data. As a pre-condition, knowing the fundamentals of programming would be helpful. The link to this series can be found here.